
目前向量化执行引擎在执行过滤操作时会有这样一些策略:
- 用一个 bitset 来标记哪些数据是被过滤选中的
- 用一个 vector 存储被命中的数据的下标
- 将命中的数据复制后传递到下一个算子
这篇文章主要讨论了前两种,文章里称之为 Bitmap(BM) 和 Selection Vector (SV)。第三种策略也有系统用,但论文中没有讨论,目前我看到的是 datafusion 用了第三种策略,最后也会讨论一下。
Filter Representation
在 BM 和 SV 中,主要有 3 种不同的策略:
- BMFull:总是对所有数据处理,未选中的数据的值未定义,优势是能充分发挥向量化的优势
- BMPartial:只对选中的数据进行处理,无法利用向量化,依然需要遍历所有下标
- SVPartial:只需要遍历选中的下标,无法利用向量化
文章中的 Manual 后缀表示手动做 SIMD 优化(利用 AVX512)而不是依赖编译期优化。其中 SVManual 可以一定程度上利用到向量化
估算模型
为了评估一个策略的计算耗时,可以用下面的公式:
其中 是数据行数, 是迭代的单位代价, 是处理数据的单位代价, 为评估耗时。
不同策略的开销也就是受这 3 个变量的影响,其中 对于给定的策略来说都是定值,而 和 取决于过滤的命中率,其中 还会很大程度上受处理的数据类型影响。
BMFull 比较特殊,它的 3 个变量都是定值。从上面也可以看出来,我们可以在不同过滤率下去比较不同策略。
比较场景
文章中定义了两种原语:
- Update:会更新命中集合的操作,也就是过滤操作,例如
where a < b - Map:会更改数据的操作,例如
select a + b
主要比较这两类原语的性能。
无数据并行场景
对于字符串处理,整数除法这样的场景,CPU 无法向量化处理多条数据,这种场景下数据处理代价会更高。
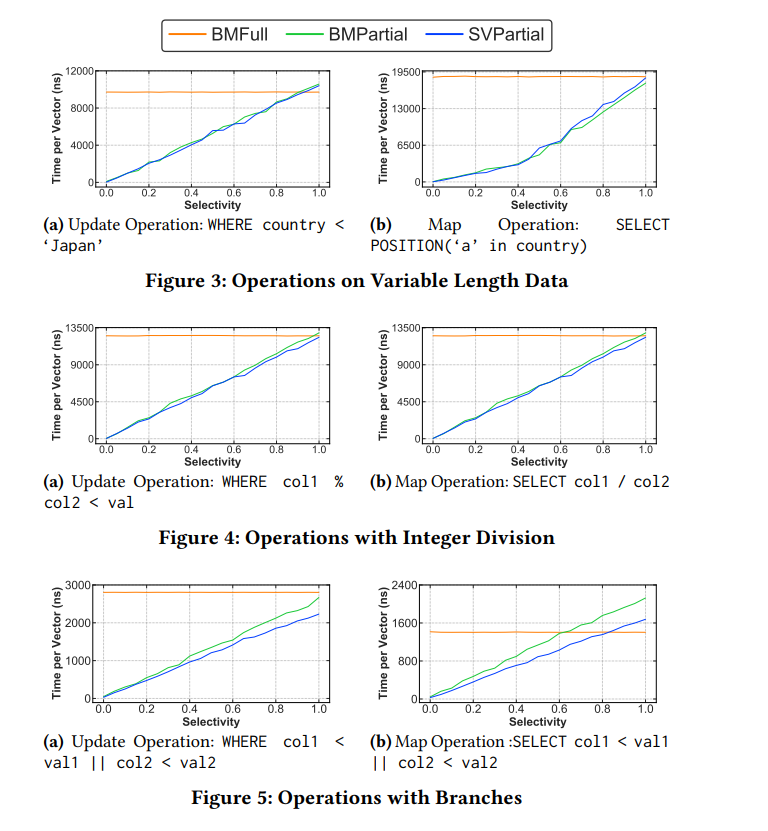
可以看到 BMPartial 和 SVPartial 的性能是很接近的,前者主要会有一个更高的遍历开销,所以 SVPartial 整体上会更优一些。在这种场景下,SVPartial 是最优策略。
低效数据并行场景
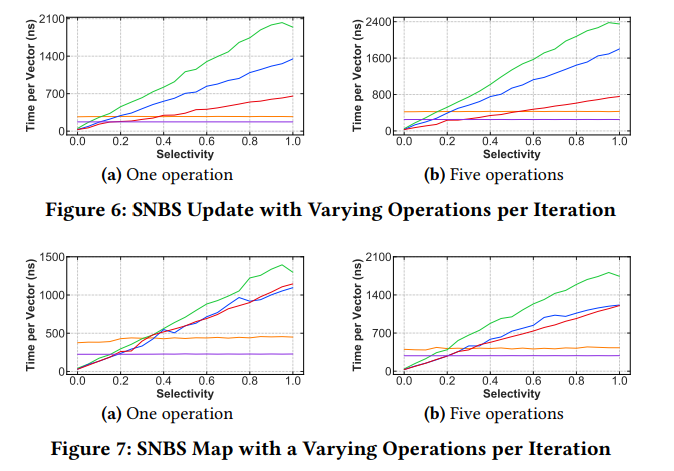
对于逻辑与或运算这样的场景,SISD 会因为短路而执行更少的代码,因此 SIMD 的开销不一定会比 SISD 更低。
可以看到整体上依然是 SVPartial 最优,BMFull 在高命中率下才会有一定优势(Map原语下)。
数据并行场景
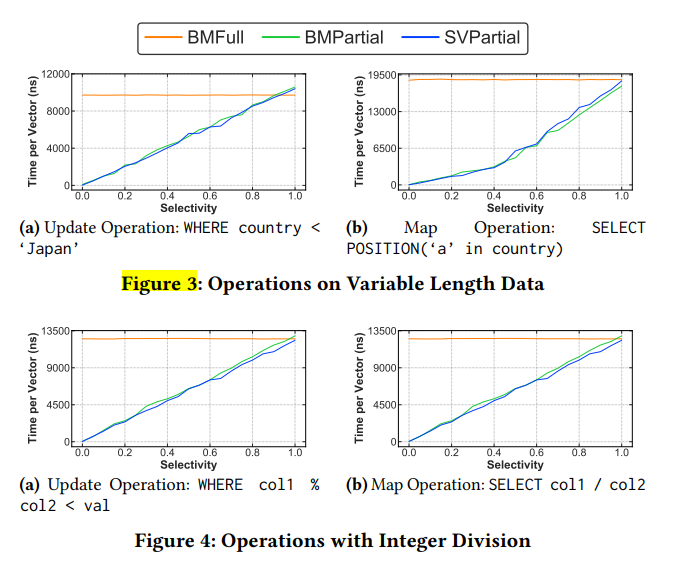
对于普通的数值运算场景,SIMD 能够充分发挥。
此时 Partial 类策略只在低命中率(< 0.2)下会有优势,更高的命中率下 BMFull 会因为向量化而具有优势。
文章中尝试了数据运算的指令数量对这个结果的影响:
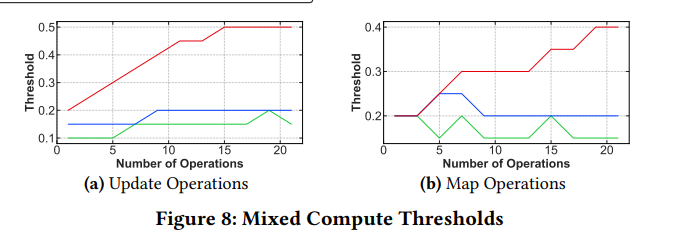
可以看到命中率阈值整体上很稳定,也就是 0.2 左右。
TPC-H 测试
文章提出了一种混合策略:对于高命中率(0.2 以上)使用 BMFull 策略(或 BMFullManual),对低命中率使用 SVManual 策略。并且使用这种策略和其它策略进行对比测试。
先放一个测试结果:
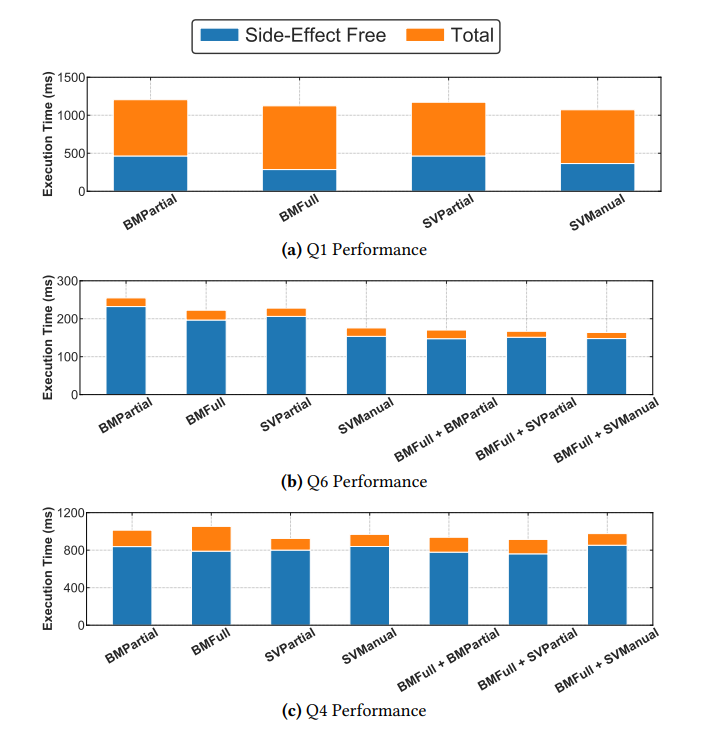
Q1 高命中率数据并行
这个测试中会有一个高命中率(0.95)的过滤,然后跟随一个有副作用(意味着无法数据并行)聚合操作。
在过滤阶段,BMFull 比 SVPartial 快 1.6x,比 SVManual 快 1.3x。但因为查询的耗时主要在最后的聚合操作,所以最终耗时接近。需要注意的是 BMPartial 和 BMFull 在最后的聚合操作上是等价的,但 BMFull 花了更多时间,这是因为 BMFull 在过滤阶段使用 AVX512 导致了 CPU 降频。
Q6 混合命中率数据并行
这个测试中第二个过滤会让命中率降低到 0.15,对于混合策略来说会触发策略切换,因此可以很好地比较混合的性能。
从测试结果中可以到,混合策略比单一策略都要快。但其中 BMFull + SVManual 比 BMFull + BMPartial 要慢(即使 SVManual 比 BMPartial 更优),这是因为 bitmap 转 selection vector 会有转换开销。
在这个测试中,因为命中率最终很低,所以查询耗时主要集中在前面的 SLDP 运算,AVX512 带来的降频对整体查询性能影响不大。
Q4 地命中率低数据并行
这个测试中命中率也会很低,并且也不能充分利用 SIMD,这种情况下 BMFull + SVPartial 是最优策略,但和 BMFull + BMPartial 差距不大。
结论
从这个文章的结论来看的话,采用混合策略可以带来大概 30% 的性能提升。而在设计策略的时候应该充分考虑到不同类型查询的影响(AVX512 带来的降频问题)。就我个人来说的话我肯定会选 BMFull + BMPartial 的策略,实现上最简单并且在多数情况下是最优策略。
最后说一下文章开头提到的复制数据的策略,用上面相同的方法去分析,这种策略应该在命中率比较低,并且数据并行的情况下会比 SVPartial 快一些,虽然多了一个数据复制的开销,但是更能充分利用向量化,毕竟 datafusion 也没有很慢。但是对于高命中率的过滤来说应该性能会比较严重,处理字符串这样的数据也会比较糟糕。
最不舒服的还是这种策略无法和 bitmap,selection vector 进行转换(除非你的数据额外再带上一个下标列,但又会增加开销了),没有什么灵活性和上升空间。